

Subscribe to our daily and weekly newsletters to receive the latest updates and exclusive content on industry-leading AI reporting. Learn more
Chinese AI startup DeepSeekwhich is known for challenging AI leaders with open source technologies, has just dropped another bombshell: a new open reasoning LLM called DeepSeek-R1.
Based on the recently introduced DeepSeek V3 Due to the mix-of-experts model, DeepSeek-R1 matches the performance of o1, OpenAI’s Frontier Reasoning LLM, on math, coding, and reasoning tasks. The best part? This happens at a much more tempting price and turns out to be 90-95% cheaper than the latter.
The release marks a major step forward in the open source area. It shows that open models continue to close the gap to closed commercial models in the artificial general intelligence (AGI) race. To demonstrate the power of its work, DeepSeek also used R1 to distill six Llama and Qwen models and take their performance to new levels. In one case, the distilled version of Qwen-1.5B outperformed the much larger GPT-4o and Claude 3.5 Sonnet models in select mathematical benchmarks.
These distilled models, along with the Main R1have been open sourced and are available on Hugging Face under an MIT license.
What does DeepSeek-R1 bring?
There is increasing focus on artificial general intelligence (AGI), a level of AI that can perform intellectual tasks like humans. Many teams are increasingly working to improve the reasoning abilities of models. OpenAI has thus taken the first significant step in this area o1 modelthat uses a thought chain-based process to address a problem. Through RL (reinforcement learning or reward-driven optimization), o1 learns to refine its chain of thought and refine the strategies it uses – ultimately learning to recognize and correct its mistakes or try new approaches when the current ones don’t work.
To continue work in this direction, DeepSeek has now released DeepSeek-R1, which uses a combination of RL and supervised fine-tuning to tackle complex reasoning tasks and achieve o1 performance.
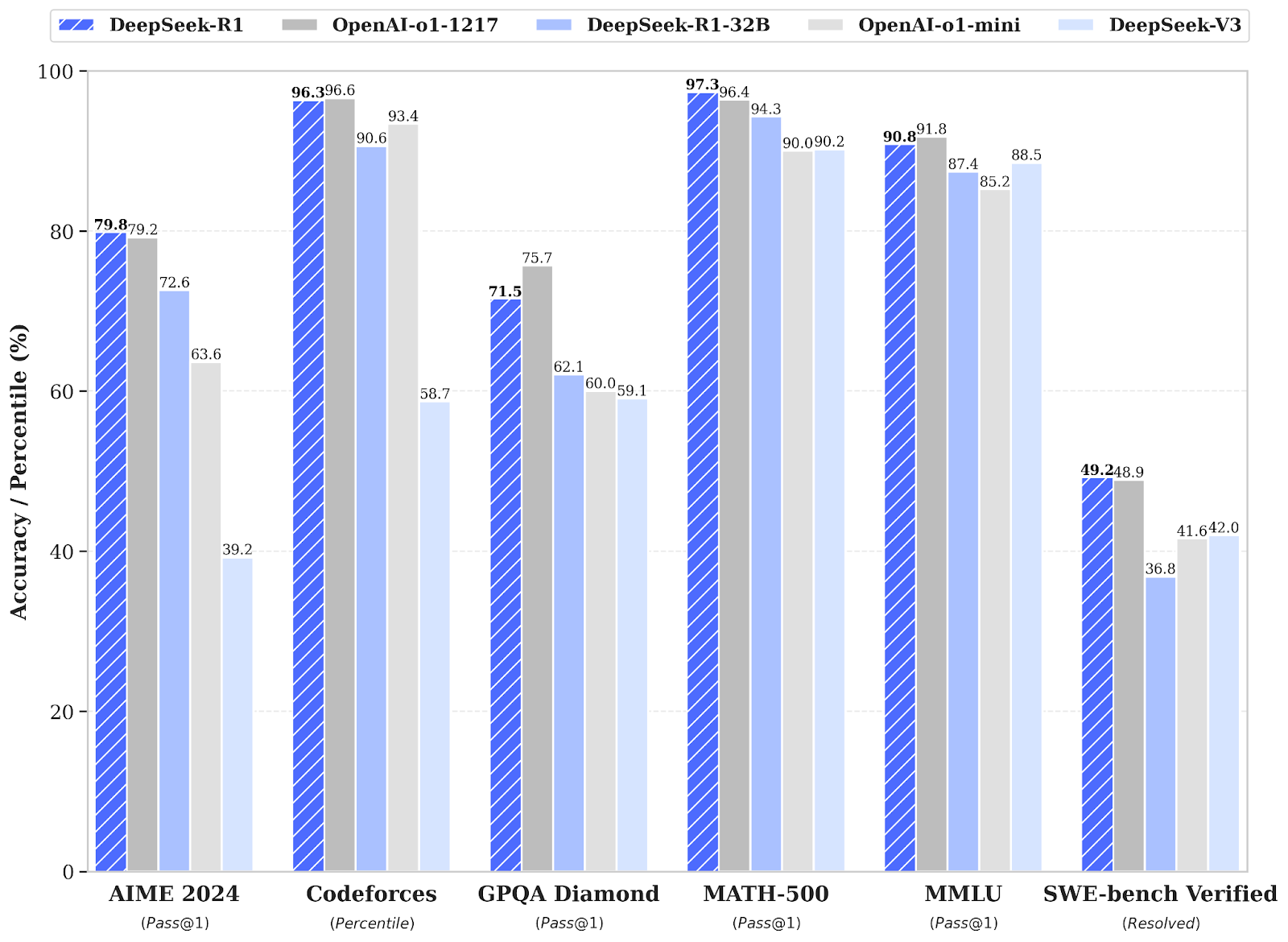
When tested, DeepSeek-R1 achieved 79.8% on the AIME 2024 math tests and 97.3% on MATH-500. It also achieved a rating of 2,029 on Codeforces – better than 96.3% of human programmers. In contrast, o1-1217 achieved 79.2%, 96.4% and 96.6% on these benchmarks, respectively.
Strong general knowledge was also demonstrated, with an accuracy of 90.8% on MMLU, just behind o1’s 91.8%.
The training pipeline
DeepSeek-R1’s reasoning power represents a major win for the Chinese startup in the US-dominated AI space, especially since all of its work is open source, including how the company trained the whole thing.
However, the work is not as easy as it sounds.
According to the paper describing the research, DeepSeek-R1 was developed as an enhanced version of DeepSeek-R1-Zero – a groundbreaking model trained exclusively through reinforcement learning.
We are living in a timeline where a non-US company is keeping the original mission of OpenAI alive – truly open, frontier research that empowers all. It makes no sense. The most entertaining outcome is the most likely.
— Jim Fan (@DrJimFan) January 20, 2025
DeepSeek-R1 not only open-sources a barrage of models but… pic.twitter.com/M7eZnEmCOY
The company initially used the DeepSeek V3 base as a base model and developed its reasoning capabilities without the use of monitored data, essentially focusing only on its self-development through a purely RL-based trial and error process. This ability, intrinsically developed from work, ensures that the model can solve increasingly complex reasoning tasks by using longer test time calculations to explore and refine its thought processes more deeply.
“During training, DeepSeek-R1-Zero naturally exhibited numerous powerful and interesting thinking behaviors,” the researchers note in the paper. “After thousands of RL steps, DeepSeek-R1-Zero shows excellent performance on reasoning benchmarks. For example, in AIME 2024, the pass@1 score increases from 15.6% to 71.0%, and under majority voting, the score further improves to 86.7%, which is in line with the performance of OpenAI-o1-0912.”
Although the original model showed improved performance, including behaviors such as reflection and exploration of alternatives, it had some problems, including poor readability and language mixing. To address this issue, the company built on the work done for R1-Zero and used a multi-stage approach that combined both supervised learning and reinforcement learning, developing the improved R1 model.
“Specifically, we are starting to collect thousands of cold start data to refine the DeepSeek V3 Base model,” the researchers explained. “We then perform argumentative RL like DeepSeek-R1-Zero. As we approach convergence in the RL process, we create new SFT data through rejection sampling at the RL checkpoint, combined with monitored data from DeepSeek-V3 in areas such as writing, factual QA and self-discovery, and then retrain DeepSeek-V3 – Basic model. After fine-tuning with the new data, the checkpoint goes through an additional RL process that takes inputs from all scenarios into account. After these steps, we obtained a probe called DeepSeek-R1, which achieves performance on par with OpenAI-o1-1217.”
Far cheaper than o1
In addition to the improved performance, which almost rivals OpenAI’s o1 in all benchmarks, the new DeepSeek-R1 is also very affordable. Specifically, OpenAI o1 costs $15 per million input tokens and $60 per million output tokens. DeepSeek Reasoner, based on the R1 model, Cost $0.55 per million input and $2.19 per million output tokens.
Sooo @deepseek_ai's reasoner model, which sits somewhere between o1-mini & o1 is about 90-95% cheaper 👀 https://t.co/ohnI6dtPRC pic.twitter.com/Qn78yIGUtt
— Emad (@EMostaque) January 20, 2025
The model can be tested as “DeepThink”. DeepSeek chat platformwhich is similar to ChatGPT. Interested users can access the model weights and code repository via Hugging Face under an MIT license or use the API for direct integration.

Source link


